
Tesserocr介绍
在使用Python进行爬虫时通常会碰到网站中图形验证码的障碍,这个时候我们可以使用光学字符识别法(OCR,Optical Character Recognition)通过扫描字符,然后通过其形状将其翻译成电子文本的过程。Tesserocr是Python中的一个OCR识别库,实际上它是对Tesseract的一个Python API封装,所以安装Tesserocr需要先安装Tesseract。

Tesseract安装
首先需要下载 Tesseract,它为 Tesserocr 提供了支持,Tesseract官网下载,其中dev为开发版,我们选择其中的稳定版下载。
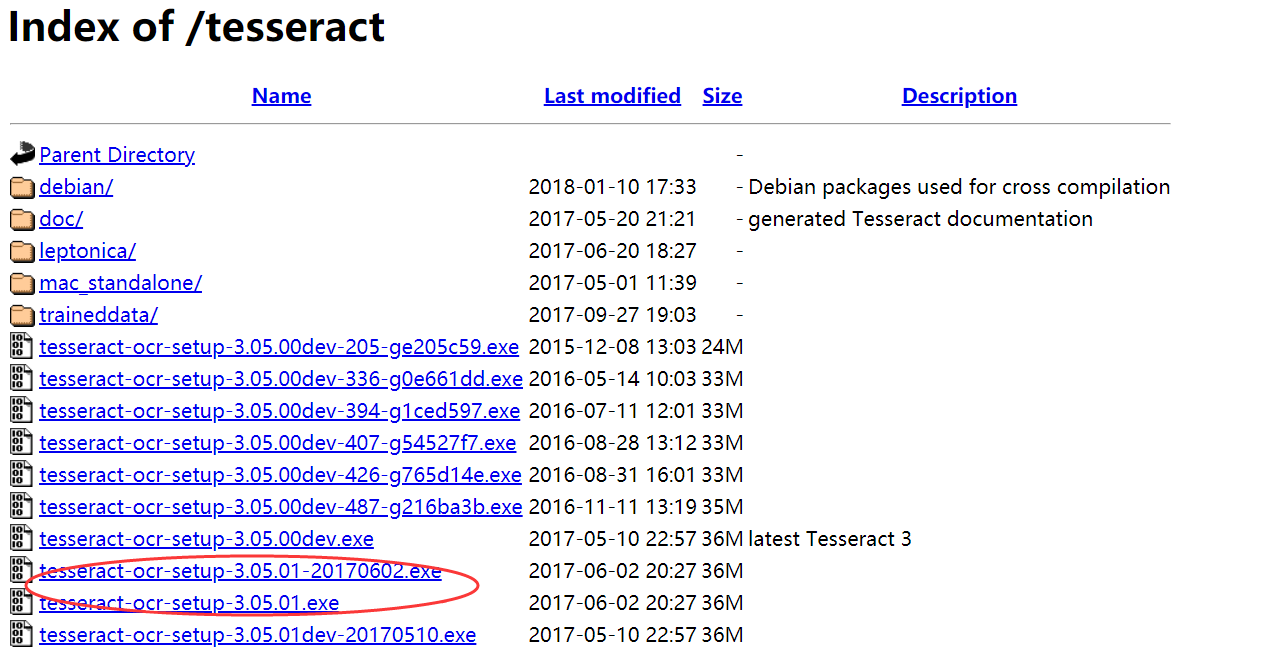
下载后直接安装即可,其中组件选择中我们勾选扩展语言包,其中数学(Math)、英文(eng)、中文简体(chi-sim)、中文繁体(chi-tro)最为重要。
Tesserocr安装
在安装Tesseract之后,我们可以直接运行下面这条命令安装Tesserocr,当然这需要你的Win10上已经安装了Python和Pip3,建议之间安装Anaconda,它们的安装过程不做介绍。
1 | pip3 install tesserocr |
如果你的环境中只有Pip3版本,可以直接使用
1 | pip install tesserocr |
验证安装
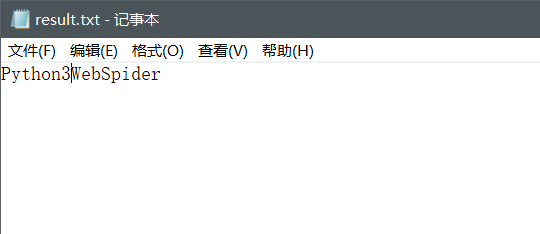
我们在网上取一个验证码图片,该图片链接为Python3WebSpider:

使用下面命令对Tesseract进行测试:
1 | tesseract image.png result -l eng |
该命令中image.png为图片文件名,result为输出记事本.txt文件名,该命令执行结果输出一个result.txt文件,看到输出内容为:
说明Tesseract安装成功,接下来验证Tesserocr库的安装,我们运行下面一段Python代码:
1 | import tesserocr |
其运行结果为:
1 | Python3WebSpider |
至此,Tesseract与Tesserocr安装成功!
安装过程中的错误
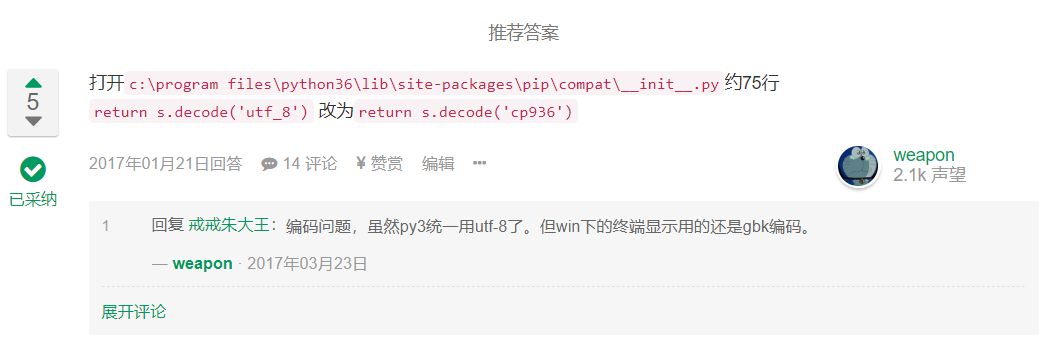
UnicodeDecodeError
在第一次运行pip install tesserocr时,我遇到了下面这个错误:
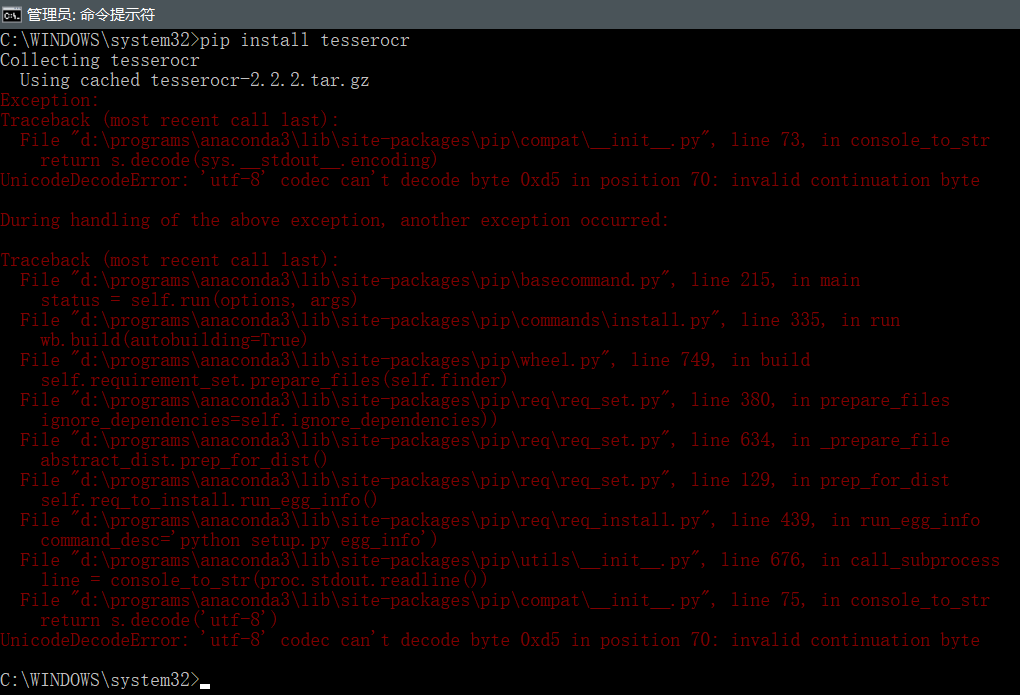
在网上找到了解决方案,链接为Windows上Python3通过pip安装包出现UnicodeDecodeError:
WinError 2
在解决上面一个错误之后,运行pip install tesserocr时又遇到了下面这个报错:
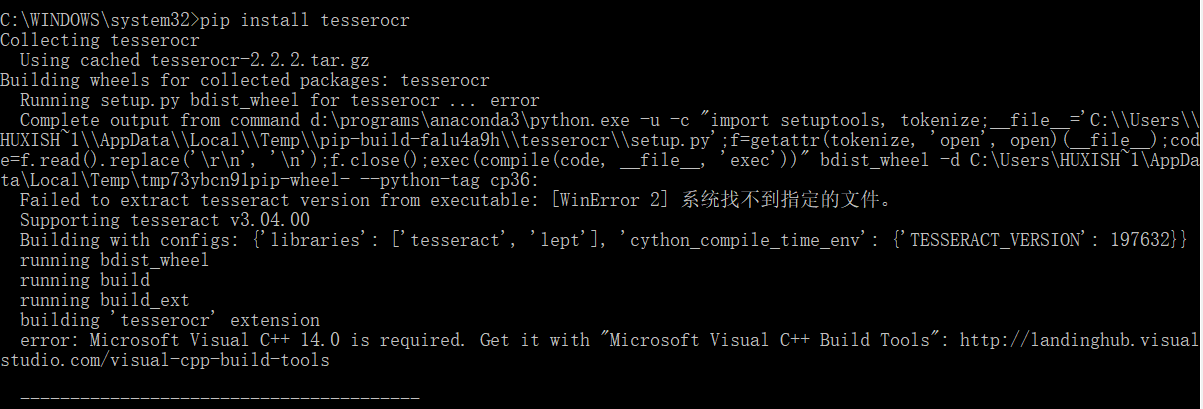
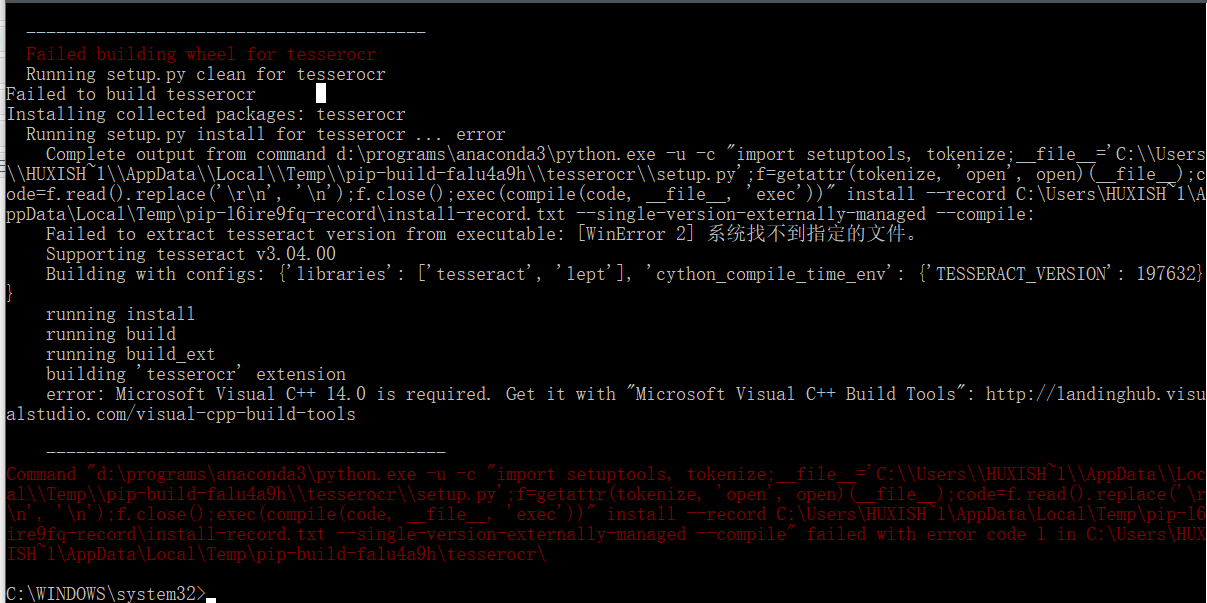
可以看到我们需要安装vc14.0,可以安装VS2015或者VS2017解决,我们选择的是安装VS2017,它很好地契合了现在微软的UWP思想,VS2017社区版。
