
前言
今天又是熊熊烈日的一天啊,只能宅在空调房里刷刷知乎。发现了一个好玩的Python接口——“itchat,它是一个开源的微信个人号接口,使用python调用微信从未如此简单”,这是官网的介绍啦。这个是itchat的Github地址,接下来便看看文档进行了一些恶趣味测试,从骚扰基友到变身聊天机器人,统计微信好友信息,最后总结出我为什么单身。
从骚扰基友到变身聊天机器人
仔细思考一哈,骚扰基友主要有三步:登录、获取目标、发送消息。嗯,可以开始了。
登录
登录有itchat.login()和itchat.auto_login()两种方法:
1 | import itchat |
1 | import itchat |
获取特定好友
我们要给好友发送消息,首先需要获取好友列表,然后从中选择想要发送消息的好友。使用itchat.get_friends()抓取好友列表,然后使用itchat.search_friends()获取特定的好友,这里使用备注名获取好友,然后取满足要求的第一个好友。
1 | friends = itchat.get_friends(update=True)[0:] # 爬取微信好友 |
发送消息
发送消息主要使用itchat.send()方法,发送的内容可以是很多种形式,包括text、img、video、file,发送成功返回True,失败返回False。对于不同的消息内容也分别有对应的方法,比如send_msg()、send_file()、send_img、send_video(),但官网推荐使用send()。下面是发送消息的代码例子,最后注释部分是群发所有好友,谨慎使用。
1 | itchat.send('Hello remarkName, I love U more than I can say!', toUserName=target['UserName']) # 发消息咯,第二个参数为userName,特定的一串hash码 |
骚扰一下
结合上面三部分代码,就可以开始打扰一下啦,全部代码如下,需要修改remarkName为目标备注名:
1 | import itchat |
首先给同在宿舍的A君来一发:
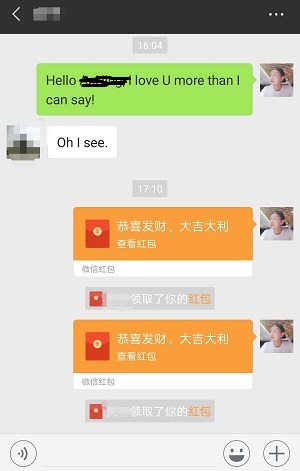
可以,认真复习的男人真是高冷,只能靠发红包来联系感情了,那就给在图书馆自习顺便看妹的H哥来一发吧:
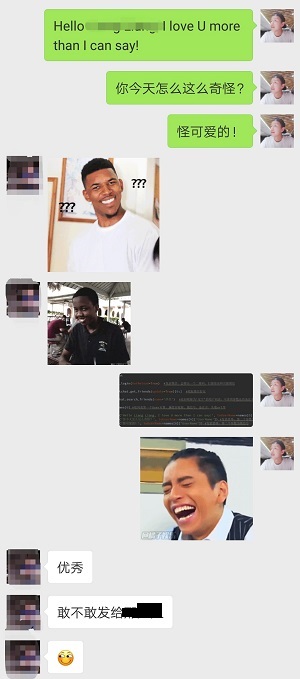
欸,果然没有认真自习,秒回。试试我们的好朋友,小哪吒X吧:
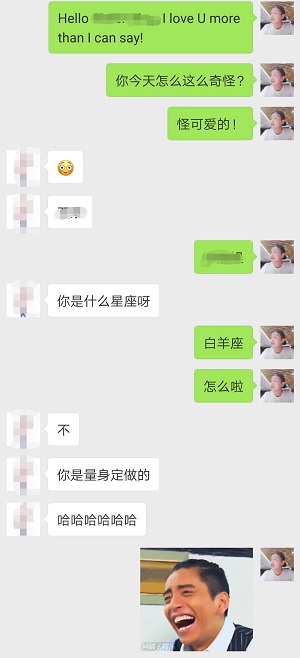
啊,没想到被小哪吒反撩了,我果然还是太年轻。
实现一个聊天机器人
这个时候,就想要实现一个自动聊天的机器人了。首先套用官方的自动回复模版,然后重写自己想要修改的方法,各个方法的作用我都写在了注释里,模版如下:
1 | import itchat, time |
模板回复Text的方法就是直接回复消息类型加消息内容,十分简单,就像小时候跟小伙伴拌嘴,你说啥他就说啥怼你,就很无聊。所以准备先修改这个方法实现自己想要的效果,哈哈哈哈哈,结果写的时候,用旧手机号注册一个小号debug太频繁,被Web微信封了,两周后解封。

所以就放弃按自己想法写的计划了,直接套用这个开源的聊天机器人项目,这个小项目是调用了图灵机器人的API,这个是API的调用文档。在回复文本信息的方法中,调用一个get_tuling_reply()方法。
1 |
|
get_tuling_reply()的代码,这个方法用来传递msg消息调用图灵机器人API,并处理图灵机器人不好使的异常情况。
1 | def get_tuling_reply(msg): |
其中调用了一个get_response()方法,这个方法就是用来调用图灵机器人API的,用来获取msg的回复内容。
1 | def get_response(msg): |
到这Text部分的修改就完成了,下面是autoreply.py的全部代码:
1 | import itchat |
代码写好了,自然要看看效果呀,就冒着被封号的危险用大号尝试了一下,用小号给大号发消息,效果截图:
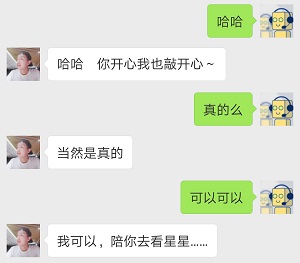
嗨呀,这么会撩,要不就用大号一直挂着好了。

统计微信好友数据
这部分主要联系一下Python画图,统计一下好友性别分布,地区分布和创建个性签名关键词云,从而在一定程度上反映我单身的原因。最后将所有好友头像拼接成一张大图,看起来不错。
爬取数据
统计对象是数据,首先需要爬取数据嘛,然后保存下来。先定一个主函数,登录Web微信,爬取好友信息保存到friends中,跟获取特定好友的步骤一样,然后遍历friends,将所有好友信息保存到一个list中,然后分别调用保存信息方法和下载头像方法。
1 | if __name__ == '__main__': |
然后是保存好友信息的方法,需要加载os、codecs、json模块:
1 | # 保存好友信息 |
下载头像的方法,需要加载os模块:
1 | # 下载好友头像 |
综合起来代码如下,添加了一个字典,将json中代表性别的1、2转化为男、女:
1 | import os |
跑一次就可以得到想要的数据咯。
男女比例
首先做一个简单的统计,得到我的票圈男女比例。首先加载数据Json文件:
1 | in_file_name = './data/friends.json' |
然后对性别进行统计,使用collections中的Counter来进行计数。然后使用pyecharts进行画图,因为pyecharts需要的参数为list,而sex_counter是一个字典,所以先把它转化为两个list。转化后调用get_pie()得到饼状图:
1 | sex_counter = Counter() # 性别 |
dict2list():
1 | def dict2list(_dict): |
get_pie():
1 | def get_pie(item_name, item_name_list, item_num_list): |
全部代码:
1 | from collections import Counter |
跑一次就可以得到好友饼状图啦,可以看出男性好友数量为女性好友数量的1.5倍,还有6.19%的没有备注性别的好友,我果然是个死直男。
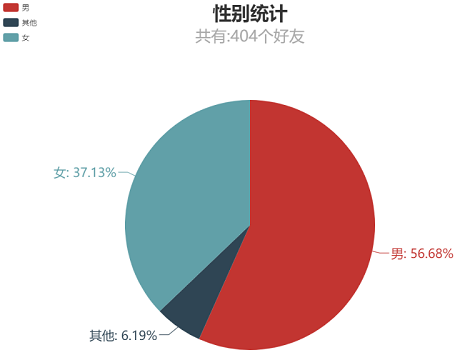
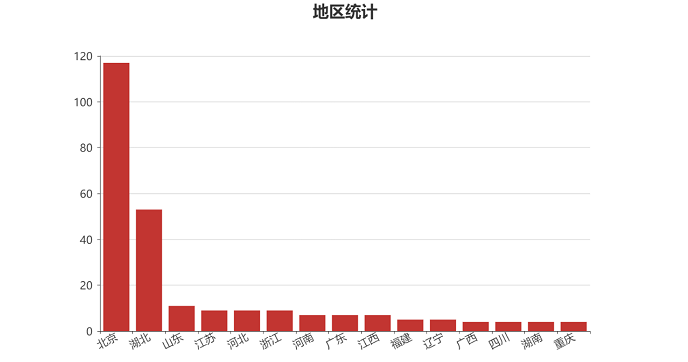
好友省份分布
与男女比例代码差不多,就直接贴代码了:
1 | from collections import Counter |
运行结果:
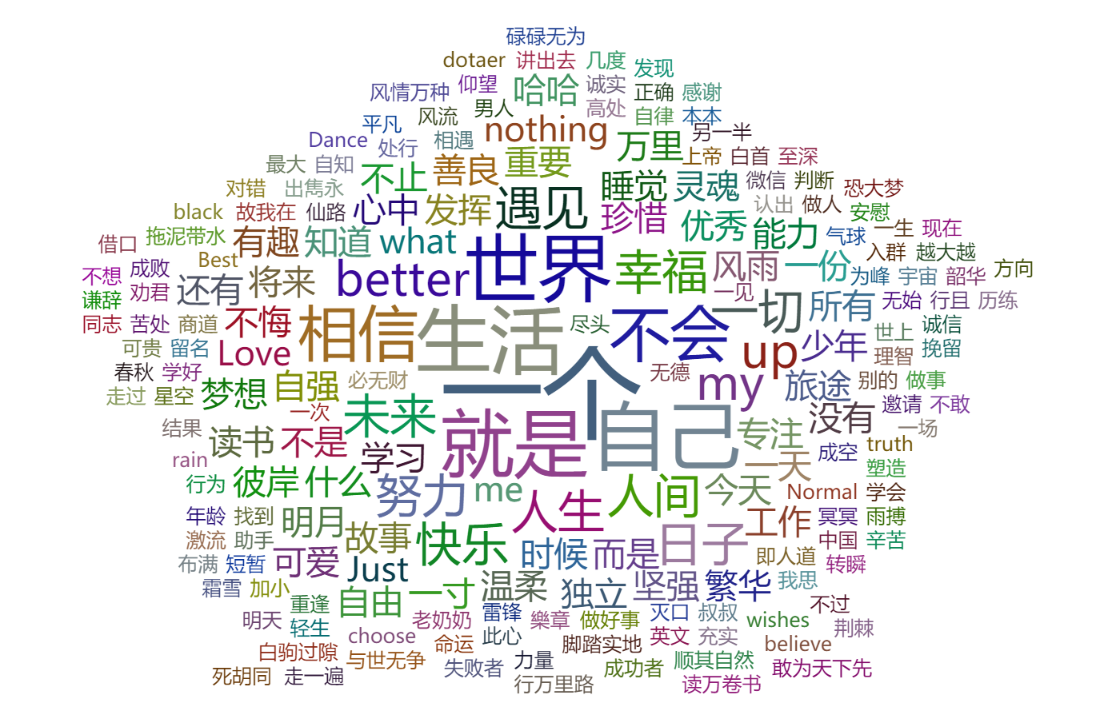
签名云
基本步骤与上面一样,主要需要使用一个叫做jieba的分词包来进行中文分词,然后发现出现了class、emoji、span等词,所以先把它们去除掉,再进行分词,也就是去除停用词。

全部代码如下:
1 | from collections import Counter |
最终结果如下,在一堆向上和小清新的关键字里面,让我眼前一亮的居然是第二行的dotaer,我果然是凭实力单的身。
合成头像
最后将所有好友头像聚合为一张图,代码如下:
1 | import math |
运行结果:

Python包清单
本文全过程在Python3环境下进行,主要依赖包如下:
- pillow: pip install pillow
- pyecharts: pip install pyecharts
- itchat: pip install itchat
- jieba: pip install jieba
我为什么单身
可能是太帅了吧,哈哈哈,
应该是太厚脸皮了。
