
背景
海量数据处理课程作业,对于给定的1998-1-人民日报语料,对于每篇文章,给出其余所有文章对它的相似度排序。为了完成这个作业,主要参考了这篇博客http://www.cnblogs.com/pinard/p/7160330.html。学习了一下gensim的基本用法,对NLP中的文本挖掘预处理有了简单的初步认识,接下来对实验过程进行总结。
word2vec原理
词向量基础
分为简单的1-of-N representation和Dristributed representation。
1-of-N representation就是有n个词,则用一个只有一个分量为1的n维向量表示,如图:
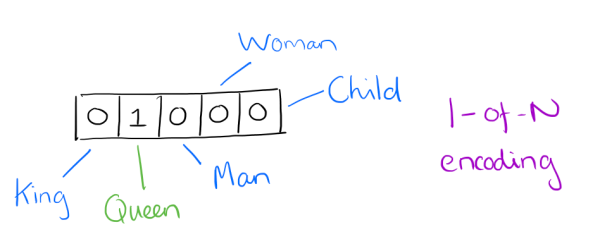
图源:cnblogs.com/pinard
Queen对应的词向量则为(0, 1, 0, 0, 0),King则为(1, 0, 0, 0, 0),Women、Man、Child同理。这种表示方法十分简单明了,然而其显著缺点便是,当词汇表规模较大时,特别是在百万级别的文本挖掘中,则需要耗费大量的空间来存储每一个词的百万维的词向量,其总的规模则为1M^2=1T,这显然是不实际的。
Dristributed representation是利用机器学习,通过学习得到每个词在相对纬度小得多的词向量。这样便可以很好地解决1-of-N representation的存储问题。举个具体的例子如图所示:
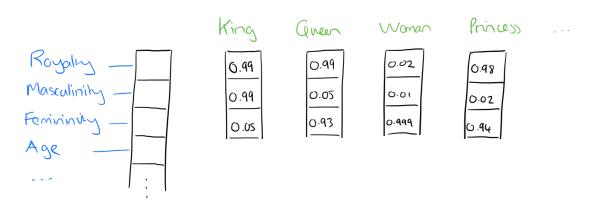
图源:cnblogs.com/pinard
这样便可以用较短的词向量来表示海量的词汇,这些词向量的具体分量均可以用神经网络来学习得到。
CBOW与Skip-Gram模型
在训练神经网络模型得到词向量的时候,主要用了CBOW和Skip-Gram两种模型。简单地来说,基于三层前馈神经网络,对词向量进行学习,神经网络的输入是目标词汇的上下文词汇的词向量,可以定义上下文的窗口大小为4,那么就输入上下文的八个词汇的词向量,比如:
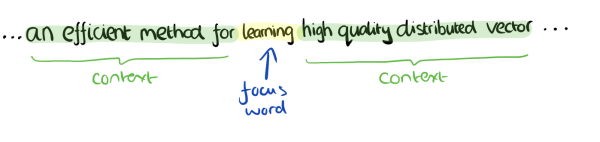
图源:cnblogs.com/pinard
则输入为an、efficient、method、for、high、quality、distributed、vector的词向量。不考虑每个词到目标词汇的距离,每个词都是平等的,使用BP算法进行训练,输出函数使用softmax函数。神经网络输出为则为learning的词向量。
相反地,Skip-Gram模型则是以learning的词向量为输入,输出上下文八个词汇的词向量。
霍夫曼树
基于对深度神经网络的学习我们知道,对神经网络的训练是十分耗时的,所以利用霍夫曼树来简化词向量生成的过程。 生成霍夫曼树的过程应该不用多讲了,就是将现有的权重最小的两个节点生成一棵树,根节点为叶子节点权重之和,然后继续寻找权重最小的两棵子树,直至所有节点生成一棵树。
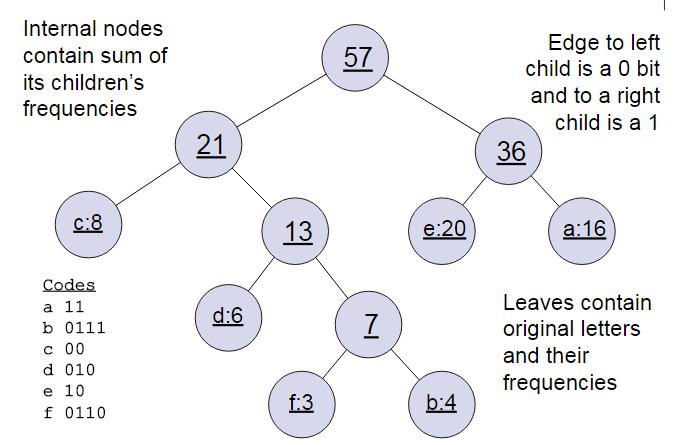
图源:cnblogs.com/pinard
一般得到霍夫曼树后我们会对叶子节点进行霍夫曼编码,由于权重高的叶子节点越靠近根节点,而权重低的叶子节点会远离根节点,这样我们的高权重节点编码值较短,而低权重值编码值较长。这保证的树的带权路径最短,也符合我们的信息论,即我们希望越常用的词拥有更短的编码。
基于Hierarchical Softmax的模型概述
word2vec对神经网络进行了两次优化,首先不采取加权和的方式,而直接将输入向量取平均值作为隐含层神经元的激活函数。其次隐含层到输出层的softmax函数采取Huffman树来计算到输出层的映射,能够大大减少计算量。这种一层一层地计算训练模型就叫做Hierarchical Softmax。其结果为对一个词向量输入,它被划为左子树的概率记为P(-),右子树的概率为P(+)=1-P(-)。回到基于Hierarchical Softmax的word2vec本身,我们的目标就是找到合适的所有节点的词向量和所有内部节点θ, 使训练样本达到最大似然。
使用gensim进行文本相似度分析
中文文本挖掘预处理
预处理一次为数据收集、除去数据非文本部分、中文分词、引入停用词、特征处理、建立分析模型。
数据收集主要有网上现有的语料,或者自己写爬虫爬数据两种途径。爬来的数据通常是HTML文件,包含大量非文本部分,比如HTML中的标签,需要对其进行清除。对于英文语料,通常只需要按空格、标点等特殊字符进行分词即可,而中文词汇之间没有像空格这样的明显标记,所以需要进行特殊的方法来分词,可以直接使用现有的Python分词包jieba来进行中文文本分词。分词之后,对于文本中的一些“着”、“和”、标点符号等无用词,进行清除,称为引入停用词。对于特征处理,则可以使用scikit-learning包来进行。有了每段文本的TF-IDF的特征向量,我们就可以利用这些数据建立分类模型,或者聚类模型了,或者进行主题模型的分析。
作业代码
gensim是一个很好用的Python NLP的包,不光可以用于使用word2vec,还有很多其他的API可以用。用它来实现求本文相似度十分简单,跑了4s,直接贴代码了。
1 | # python3.6 |
