配置Spark不同任务driver日志输出到不同文件
第一步:配置log4j.properties输出文件名设为一个占位符:
log4j.appender.DRFA.File=log/${logfilename}.log
第二步:在spark-submit时传递一个参数:
—driver-java-options "-Dlogfilename=${JOB_NAME}"
通过设置JOB_NAME的值来动态设置任务log输出文件。

配置Spark不同任务driver日志输出到不同文件
第一步:配置log4j.properties输出文件名设为一个占位符:
log4j.appender.DRFA.File=log/${logfilename}.log
第二步:在spark-submit时传递一个参数:
—driver-java-options "-Dlogfilename=${JOB_NAME}"
通过设置JOB_NAME的值来动态设置任务log输出文件。
更新MacOS后,使用Git命令时报错:
xcrun: error: invalid active developer path (/Library/Developer/CommandLineTools), missing xcrun at: /Library/Developer/CommandLineTools/usr/bin/xcrun
使用如下命令解决:
xcode-select --install
这是由于每次更新Mac系统Xcode都会被卸载,Mac中Git是基于Xcode line tools运行的,使用其他依赖Xcode line tools的工具应该也会出现同样的错误,所以更新完系统之后记得重装一次Xcode呀。
今天又是熊熊烈日的一天啊,只能宅在空调房里刷刷知乎。发现了一个好玩的Python接口——“itchat,它是一个开源的微信个人号接口,使用python调用微信从未如此简单”,这是官网的介绍啦。这个是itchat的Github地址,接下来便看看文档进行了一些恶趣味测试,从骚扰基友到变身聊天机器人,统计微信好友信息,最后总结出我为什么单身。
最近学的很无聊,就又想折腾一下我稚嫩的Blog,零零总总写了三十多篇文章,虽然都是辣鸡,但还是想做一个统计,能够在主页观察到每篇文章的阅读量,能直观看到哪怕一点点增量,那也能带来很大的满足感啊。于是Google了一下,在一个叫Doublemine的博客上发现原来Next主题支持一个叫LeanCloud的云服务商提供的统计功能,于是便做了一点微小的工作,达到了下面的效果。这篇教程在Doublemine的博客已经很详细,但是LeanCloud的UI进行了不小的更新,一些功能布局发生了变化,所以索性就根据新的UI再写一篇辣鸡博文。
你是产品经理,目前正在带领一个团队开发新的产品。不幸的是,你的产品的最新版本没有通过质量检测。由于每个版本都是基于之前的版本开发的,所以错误的版本之后的所有版本都是错的。
假设你有 n 个版本 [1, 2, ..., n],你想找出导致之后所有版本出错的第一个错误的版本。
你可以通过调用 bool isBadVersion(version) 接口来判断版本号 version 是否在单元测试中出错。实现一个函数来查找第一个错误的版本。你应该尽量减少对调用 API 的次数。
示例:
1 | 给定 n = 5,并且 version = 4 是第一个错误的版本。 |
海量数据处理课程作业,对于给定的1998-1-人民日报语料,对于每篇文章,给出其余所有文章对它的相似度排序。为了完成这个作业,主要参考了这篇博客http://www.cnblogs.com/pinard/p/7160330.html。学习了一下gensim的基本用法,对NLP中的文本挖掘预处理有了简单的初步认识,接下来对实验过程进行总结。
分为简单的1-of-N representation和Dristributed representation。
1-of-N representation就是有n个词,则用一个只有一个分量为1的n维向量表示,如图:
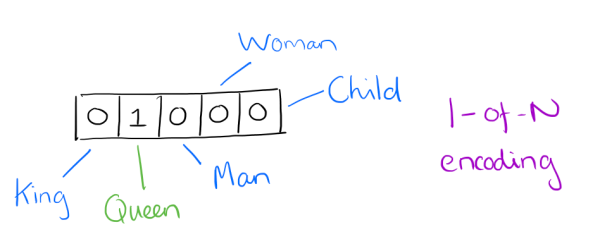
图源:cnblogs.com/pinard